
Stack
过于常见了,记录一下不常见的方式
SROP
利用sigreturn去实现控制
攻击原理
仔细回顾一下内核在 signal 信号处理的过程中的工作,我们可以发现,内核主要做的工作就是为进程保存上下文,并且恢复上下文。这个主要的变动都在 Signal Frame 中。但是需要注意的是:
由于内核与信号处理程序无关 (kernel agnostic about signal handlers),它并不会去记录这个 signal 对应的 Signal Frame,所以当执行 sigreturn 系统调用时,此时的 Signal Frame 并不一定是之前内核为用户进程保存的 Signal Frame。
Signal Frame 被保存在用户的地址空间中,所以用户是可以读写的。
Stack Pivoting
栈迁移
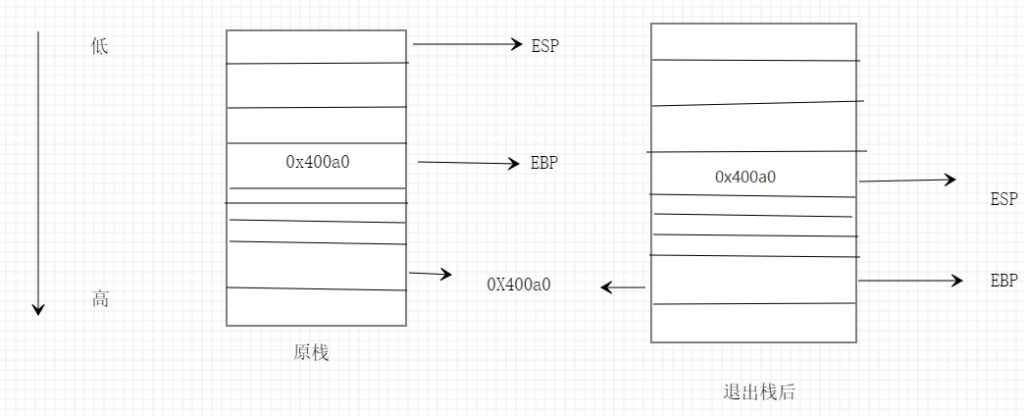
首先栈执行命令是从 esp 开始向 ebp 方向逐条执行,也就是从低地址到高地址逐条执行。触发栈迁移的关键指令:leave|ret,等效于mov esp ebp; pop ebp; ret;,作用是将 ebp 赋值给 esp ,并弹出 ebp 。
正常情况下退出栈时,esp 指向 ebp 所在位置,ebp 指向 ebp 所存储的位置。等同于执行一个 leave ret 的效果。
Fmt
Heap
堆的申请
- Top Chunk:程序第一次malloc的时候,heap分成两块,一块给用户,一块就是Top Chunk,再次申请堆块要是没有合适的空间便会使用 Top Chunk
- 申请到的一块堆内存的内存的起始地址 != 可以写入数据的起始地址,因为堆块头部(0x10大小)会记录一些信息。
- 自己申请的大小 <= 实际的大小 ,会有一个取整
malloc()函数会返回可写地址开始的地址free()不会删掉对应堆块的内容。对应堆块会变成free chunk并且加上了类似xxx bin的名字,这类堆块释放后如果挨着一个也被释放的堆块或者Top Chunk就会合并,除了Fast Bin这个特例,它不会轻易合并。void* calloc(size_t nitems, size_t size)函数,返回一个(一组)指向它(它们)的指针,和malloc不同的是,malloc不会设置内存为0,calloc会置零realloc(void* ptr, size_t size)改变堆块大小
#include <stdio.h>
#include <stdlib.h>
int main(){
int *a = NULL;
int *b = NULL;
a = (int *)malloc(0x100);
b = (int *)malloc(0x200);
memset(a, 'a', 0x100);
memset(b, 'b', 0x200);
b = realloc(b, 0x256); //扩大但后面有空间
a = realloc(a, 0x512); //扩大但后面没空间
b = realloc(b, 0x200); //缩小但后面无空间
a = realloc(a, 0x486); //缩小但后面有空间
return 0;
}可以用gdb调试一下这个程序就知道realloc在这四种情况下会怎么分配内存。
- 扩大但后面有空间:直接从Top Chunk里面拿
- 扩大但后面没空间:类似于free+malloc,会把原先的复制到新的堆块,原先的归到unsortedbin
- 缩小但后面无空间:中间夹着那段释放,视大小变成fastbin,最后变成unsortedbin
- 缩小但后面有空间:与Top Chunk合并
特殊情况:
- ptr = NULL,size != 0:相当于malloc
- ptr != NULL,size = 0:相当于free
Bin
bin大小范围
- fastbin大小范围0x20~0x80
- largebin大于等于1024字节(0x400)的chunk称之为large chunk。
- smallbin小于1024字节(0x400)的chunk称之为small chunk,small bin就是用于管理small chunk的。
- unsortedbin当释放较小或较大的chunk的时候,如果系统没有将它们添加到对应的bins中,系统就将这些chunk添加到unsorted bin中
tcache
tcache 是 glibc 2.26 (ubuntu 17.10) 之后引入的一种技术
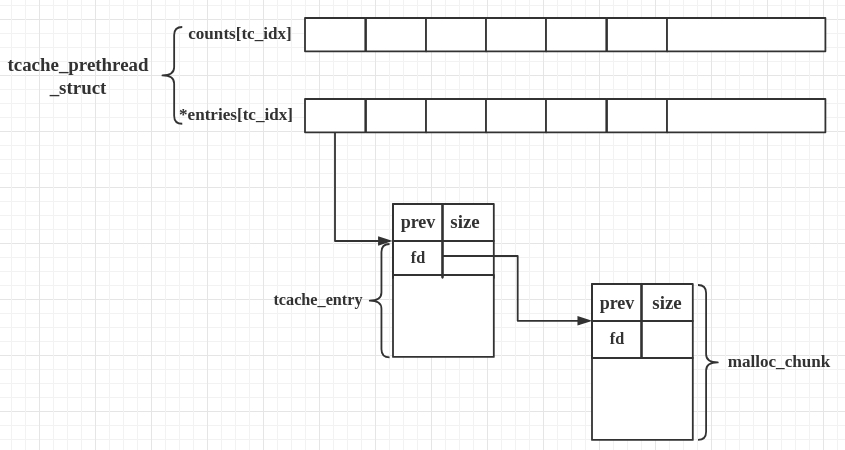
tcache_entry
/* We overlay this structure on the user-data portion of a chunk when
the chunk is stored in the per-thread cache. */
typedef struct tcache_entry
{
struct tcache_entry *next; // 指向下一个空闲的chunk的user data,而不是chunk head
} tcache_entry;而且,tcache_entry 会复用空闲 chunk 的 user data 部分。
tcache_perthread_struct
/* There is one of these for each thread, which contains the
per-thread cache (hence "tcache_perthread_struct"). Keeping
overall size low is mildly important. Note that COUNTS and ENTRIES
are redundant (we could have just counted the linked list each
time), this is for performance reasons. */
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
# define TCACHE_MAX_BINS 64
static __thread tcache_perthread_struct *tcache = NULL;tcache_entry用单向链表的方式链接了相同大小的处于空闲状态(free 后)的 chunk,这一点上和 fastbin 很像。counts记录了tcache_entry链上空闲 chunk 的数目,每条链上最多可以有 7 个 chunk。
基本工作方式
- 第一次 malloc 时,会先 malloc 一块内存用来存放
tcache_perthread_struct。 - free 内存,且 size 小于 small bin size 时
- tcache 之前会放到 fastbin 或者 unsorted bin 中
- tcache 后:
- 先放到对应的 tcache 中,直到 tcache 被填满(默认是 7 个)
- tcache 被填满之后,再次 free 的内存和之前一样被放到 fastbin 或者 unsorted bin 中
- tcache 中的 chunk 不会合并(不取消 inuse bit)
- malloc 内存,且 size 在 tcache 范围内
- 先从 tcache 取 chunk,直到 tcache 为空
- tcache 为空后,从 bin 中找
- tcache 为空时,如果
fastbin/smallbin/unsorted bin中有 size 符合的 chunk,会先把fastbin/smallbin/unsorted bin中的 chunk 放到 tcache 中,直到填满。之后再从 tcache 中取;因此 chunk 在 bin 中和 tcache 中的顺序会反过来
在开启tcache的时候,会先去看看是否符合tcache,再去寻找有无对应chunk,若没有再进行其他流程
tcache 的优先级很高,比 fastbin 还要高
遵循LIFO
tcache_get()
链表取头然后count–
tcache_put()
放到链表头然后count++
这两个函数会在函数 _int_free 和 __libc_malloc 的开头被调用,其中 tcache_put 当所请求的分配大小不大于0x408并且当给定大小的 tcache bin 未满时调用
- 内存申请:
在内存分配的 malloc 函数中有多处,会将内存块移入 tcache 中。
(1)首先,申请的内存块符合 fastbin 大小时并且在 fastbin 内找到可用的空闲块时,会把该 fastbin 链上的其他内存块放入 tcache 中。
(2)其次,申请的内存块符合 smallbin 大小时并且在 smallbin 内找到可用的空闲块时,会把该 smallbin 链上的其他内存块放入 tcache 中。
(3)当在 unsorted bin 链上循环处理时,当找到大小合适的链时,并不直接返回,而是先放到 tcache 中,继续处理。
一个利用思路
- getshell:
__malloc_hook在libc的data段里面,调用malloc的时候会跳转到__malloc_hook里面的地址,只要把这个__malloc_hook改成system或者execve就能getshell
但是要怎么知道这个的地址呢?main_arena + 0x58(libc2.23版本,对应Ubuntu16)这个地址有,这个地址是unsorted_bin的表头,而main_arena - 0x10就是这个malloc_hook的地址
就有:malloc_hook_addr = unsortedbin_addr - 0x58 - 0x10 - 更改
__malloc_hook:
fastbin attack
伪造一个堆块,然后使得fd指向__malloc_hook-0x23
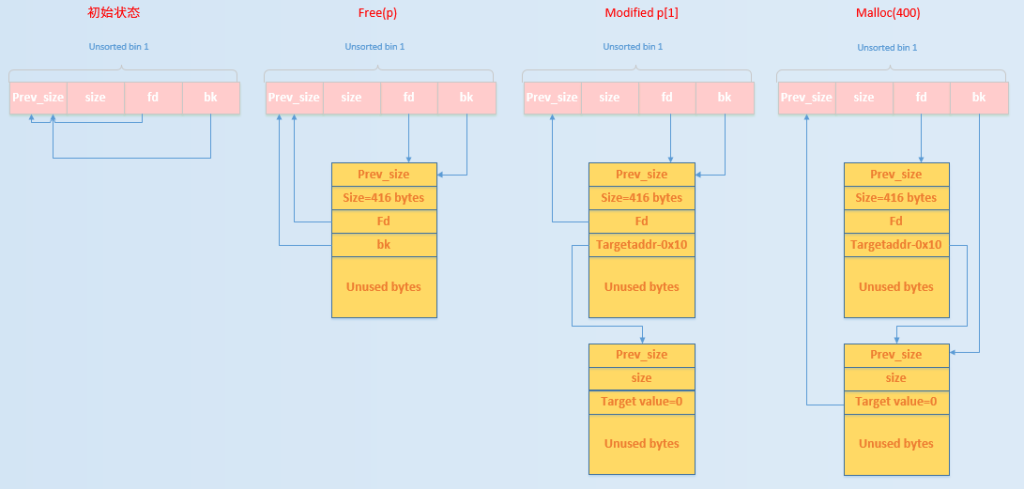
Unsorted Bin Attack
在 glibc/malloc/malloc.c 中的 _int_malloc 有这么一段代码,当将一个 unsorted bin 取出的时候,会将 bck->fd 的位置写入本 Unsorted Bin 的位置。
/* remove from unsorted list */
if (__glibc_unlikely (bck->fd != victim))
malloc_printerr ("malloc(): corrupted unsorted chunks 3");
unsorted_chunks (av)->bk = bck; //此处bck是被使用的chunk块的bk指向的地址
bck->fd = unsorted_chunks (av);看后两行就好了,unsorted_chunk的bk指针指向的是它下一个被释放的chunk的块地址(bck),后一个被释放的chunk的fd指针指向的是unsorted_chunk的块地址。如果我们能够控制unsorted_chunk的bk,那么就意味着可以将unsorted_chunks (av),即unsorted_chunk的块地址写到任意可写地址内
unlink
unlink操作就是把两个物理相邻的堆块合并
虽然libc源码很复杂但是整个操作下来基本是下面这点,下面基本是32bits,64bits要注意偏移

FD = P -> fd
BK = P -> bk
FD -> bk = BK
BK -> fd = FD
--------下面是非指针形式(32 bits)----------
FD = *(P + 8)
BK = *(P + 12)
*(FD + 12) = BK
*(BK + 8) = FD
--------下面是非指针形式(64 bits)----------
FD = *(P + 0x10)
BK = *(P + 0x18)
*(FD + 0x18) = BK
*(BK + 0x10) = FD怎么利用捏?
远古时代
- 首先能够修改free掉的堆块
- P的fd指针要修改为 (target addr – 12), bk指针修改成修改的内容
FD = P -> fd,FD就变成了我们改的地址
BK = P -> bk,BK就变成了我们改的内容
FD -> bk = BK,FD+12就变成了BK
还要保证BK+8需要可写
但是,现实是残酷的。。
// fd bk
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \这下不能随心所欲了
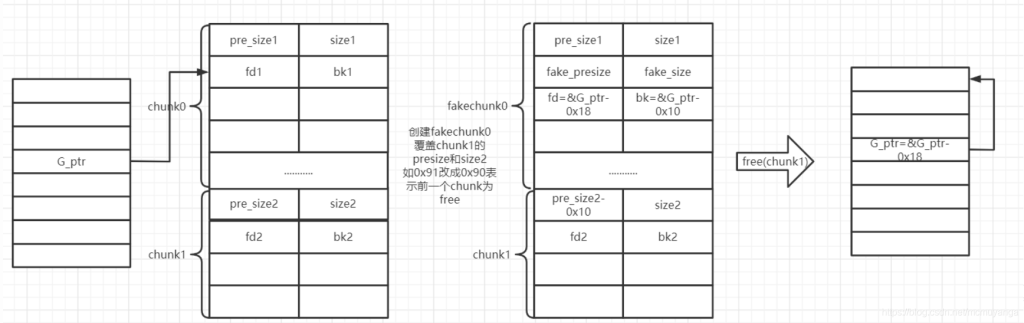
思路转变一下,我们修改P的位置,让系统对于堆块的指针指向需要的位置 :
(in 64bits下)设指向可UAF chunk的指针的地址为ptr
修改fd为ptr-0x18
修改bk为ptr-0x10
触发unlink,ptr处的指针会变成ptr-0x18
如果实在没有理解,就记得:通过伪造堆块,unlink之后,target_ptr = &target_ptr – 0x18
tcache attack
根据tcache_get源码:
static __always_inline void *
tcache_get (size_t tc_idx)
{
tcache_entry *e = tcache->entries[tc_idx];
assert (tc_idx < TCACHE_MAX_BINS);
assert (tcache->entries[tc_idx] > 0);
tcache->entries[tc_idx] = e->next;
--(tcache->counts[tc_idx]);
return (void *) e;
}就只有两个检查,一个是tc_idx大小合法,一个是指针是否不为0
tcache poisoning
通过覆盖tcache的next,就能malloc任意地址
tcache dup
因为tcache_put不检查,所以可以对同一个chunk多次free,造成cycliced list
libc Leak
多了tcache,再想leak libc版本就要去把tcache填满之后打印就行了
评论